온디바이스 함수 호출, Google AI Edge Gallery로 모바일 AI 에이전트 구현하기
모바일에서 AI가 '행동'하기 시작했다
AI가 단순히 텍스트를 생성하는 것을 넘어, 실제로 앱을 열고 시스템 설정을 바꾸고 캘린더에 일정을 추가하는 시대가 왔어요. 이 모든 것이 서버 없이, 내 스마트폰 위에서 실행된다면 어떨까요? 온디바이스 함수 호출(On-Device Function Calling)은 바로 그 가능성을 현실로 만드는 기술이에요. 네트워크 지연도, 개인정보 유출 위험도 없이 자연어 명령 하나로 OS 기능을 직접 제어할 수 있죠. Google은 최근 AI Edge Gallery를 대폭 업데이트하며 이 기술을 개발자 누구나 체험하고 확장할 수 있도록 공개했어요. 이번 글에서는 FunctionGemma의 구조, 성능 벤치마크, 그리고 실제 커스텀 에이전트를 만드는 방법까지 깊이 있게 살펴볼게요.

FunctionGemma 270M — 왜 이 숫자가 중요한가
전통적인 함수 호출(Function Calling) 모델은 수십억 개의 파라미터를 요구해서, 모바일 하드웨어의 메모리와 배터리 한계를 훌쩍 넘겼어요. 이걸 모바일에 구겨 넣으면서도 정확도를 유지하는 것이 핵심 엔지니어링 과제였죠.
Google이 내놓은 해답이 바로 FunctionGemma 270M이에요. 겨우 2억 7천만 개의 파라미터로 자연어를 OS 툴 인텐트(intent)로 변환하는 데 특화된 모델이에요. 성능 수치를 보면 왜 주목받는지 바로 알 수 있어요.
- Pixel 7 Pro CPU 기준: 프리필(prefill) 1,916 tokens/sec
- 디코드(decode) 속도: 142 tokens/sec
- 완전 오프라인 동작 — 네트워크 핑(ping) 제로
- iOS/Android 크로스플랫폼 지원 (LiteRT 기반)
이 숫자가 의미하는 건 단순한 벤치마크 수치가 아니에요. 사용자가 "내일 오후 2시 30분에 요리 수업 캘린더 등록해줘"라고 말하면, 모델이 네트워크를 거치지 않고 즉시 createCalendarEvent(time: "14:30", title: "요리 수업") 형태의 함수 호출을 생성해 OS에 전달하는 속도가 이 수준이라는 거예요.
LiteRT가 이걸 가능하게 하는 방법
리터트(LiteRT)는 TensorFlow Lite의 후속으로, CPU와 GPU 가속을 통합 관리해요. AI Edge Gallery의 벤치마크 기능을 사용하면 내 기기에서 직접 prefill/decode 토큰 수와 실행 횟수를 조정하며 실측값을 확인할 수 있어요.
// 벤치마크 실행 방법
1. Gallery 앱 좌상단 햄버거 메뉴 탭
2. Benchmark 타일 선택
3. 다운로드 가능한 모델 목록에서 FunctionGemma 선택
4. prefill 토큰 수, decode 토큰 수, 실행 횟수 설정 후 실행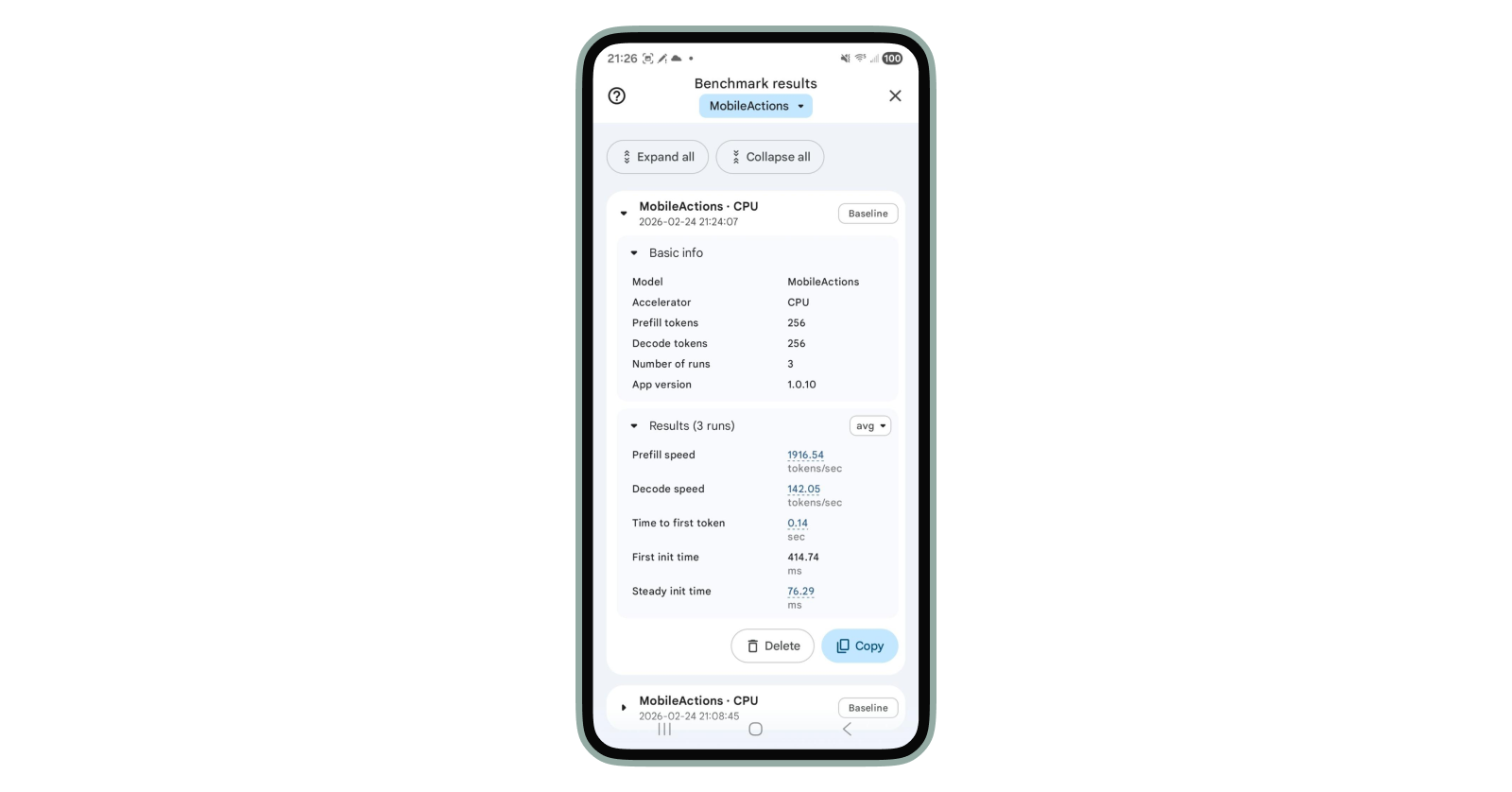
Mobile Actions & Tiny Garden — 실제 구현 패턴 분석
온디바이스 함수 호출을 가장 잘 보여주는 두 가지 데모가 Gallery에 탑재되어 있어요. 단순한 쇼케이스가 아니라, 실제 앱에 적용할 수 있는 구조적 패턴을 담고 있어요.
Mobile Actions — 자연어 → OS 인텐트 변환
Mobile Actions는 다음과 같은 명령어를 처리해요.
"샌프란시스코 공항 지도에서 보여줘"→ 지도 앱 인텐트 실행"내일 오후 2시 30분 요리 수업 캘린더 등록"→ 캘린더 이벤트 생성"손전등 켜줘"→ 시스템 플래시 토글
모델은 자연어를 파싱해서 어떤 OS 툴이나 앱 인텐트를 실행해야 하는지 예측해요. 개발자 관점에서 주목할 점은 이 함수 스키마(schema)를 커스텀 앱 로직에 맞게 교체할 수 있다는 거예요.
Tiny Garden — 도메인 특화 함수 호출
Tiny Garden은 음성 명령으로 가상 농장을 관리하는 미니게임이에요. "맨 위 줄에 해바라기 심고 물 줘"라는 명령이 들어오면 모델이 이걸 분해해요.
# 모델이 생성하는 함수 호출 시퀀스 예시
plantCrop(crop="sunflower", row=0, cols=[0,1,2,3,4])
waterCrop(row=0, cols=[0,1,2,3,4])이 패턴이 흥미로운 이유는 모델이 게임 도메인에 특화된 커스텀 함수 스펙을 학습 없이 컨텍스트 내에서 처리한다는 점이에요. 자체 앱의 API를 함수 스키마로 정의하면, 동일한 모델이 그 로직에 맞게 동작해요.
iOS 지원과 크로스플랫폼 전략
이번 업데이트의 또 다른 핵심은 Google AI Edge Gallery의 iOS 정식 출시예요. 기존 Android 전용이었던 모든 기능이 Apple 하드웨어에서도 동일하게 동작해요.
- 멀티턴 AI 채팅 (Multi-turn AI Chat)
- 이미지 질의 (Ask Image)
- 로컬 음성 전사 (Audio Scribe)
- Mobile Actions & Tiny Garden 에이전트 데모
Google AI Edge 스택은 단일 코드베이스로 iOS와 Android 모두를 지원하기 때문에, 개발자 입장에서 플랫폼 분기 작업을 최소화할 수 있어요. 프라이버시 측면에서도 모든 추론이 로컬에서 이뤄지므로, 민감한 사용자 데이터가 외부 서버로 전송될 위험이 없어요.
나만의 에이전트를 만들려면
- AI Edge Gallery 앱 다운로드 (Android / iOS App Store)
- Gallery 소스코드 포크 — 자신의 앱 로직에 맞게 함수 스키마 정의
- FunctionGemma 파인튜닝(fine-tuning) 적용 — 도메인 특화 함수에 최적화
- LiteRT 벤치마크로 기기별 성능 검증
- GitHub 이슈/PR로 커뮤니티 기여 또는 피드백 제출
마무리
온디바이스 함수 호출은 더 이상 미래 기술이 아니에요. 270M 파라미터의 FunctionGemma가 Pixel 7 Pro에서 초당 142토큰을 디코딩하는 지금, 모바일 AI 에이전트의 진입 장벽은 의미 있는 수준으로 낮아졌어요. iOS 지원 확대와 인앱 벤치마크 기능 추가로 개발자가 직접 검증하고 확장하기도 훨씬 쉬워졌죠. 이제 서버 없이도 동작하는 자신만의 로컬 에이전트를 만들어볼 차례예요.